Harvard Aging Brain Study (Summer 2024)
Served as a research intern on the Data Analytics team for the Harvard Aging Brain Study . Contributed to the initiation and development of a machine learning project focused on cross-modality MRI synthesis (T1-T2), while supporting the team’s broader data processing and statistical analyses.
My Contributions
- Preprocessed NIfTI neuroimages, including normalization and registration to MNI space
- Adapted a synthetic diffusion model for cross-modality MRI synthesis (T1-T2) to reduce the need for additional scans
- Performed statistical analysis and visualization in R on neurological datasets
Perception Control & Cognition Lab (May 2023-May 2024)
Conducted research in computational social science investigating whether large language models (LLMs) can simulate human behavior when conditioned on demographic attributes such as age, race, education, religion, ideology, and income, building upon prior lab work published in Out of One, Many: Using Language Models to Simulate Human Samples (2022).
My Contributions
- Crafted and optimized prompts for LLMs (e.g., LLaMA-2, GPT-4, and Claude) to model human behavior across demographic groups.
- Designed and conducted LLM-to-LLM conversational experiments, comparing synthetic dialogues to real human conversations using statistical metrics (accuracy, chi-squared) and text analysis (sentiment and content evaluation).
- Fine-tuned large-scale LLaMA models on a high-performance computing (HPC) cluster with SLURM for distributed training.
- Optimized LLM experimentation by testing prompts at small scale before running full 1000-conversation experiments, reducing costs and speeding up iteration.
Primary Study: Mimicking Conversational Dynamics
- Awarded 1st Place – Data Science Session at the Brigham Young University Student Research Conference (Presentation Slides).
- Used the Persuasion For Good dataset, which contains multi-turn conversations between a persuader and a persuadee, ending with a donation decision.
- Generated simulated conversations using GPT-4 to evaluate whether LLMs can replace or augment costly human subject studies.
- Each simulated dialogue consisted of ~10 conversational turns followed by a binary donation outcome.
Results
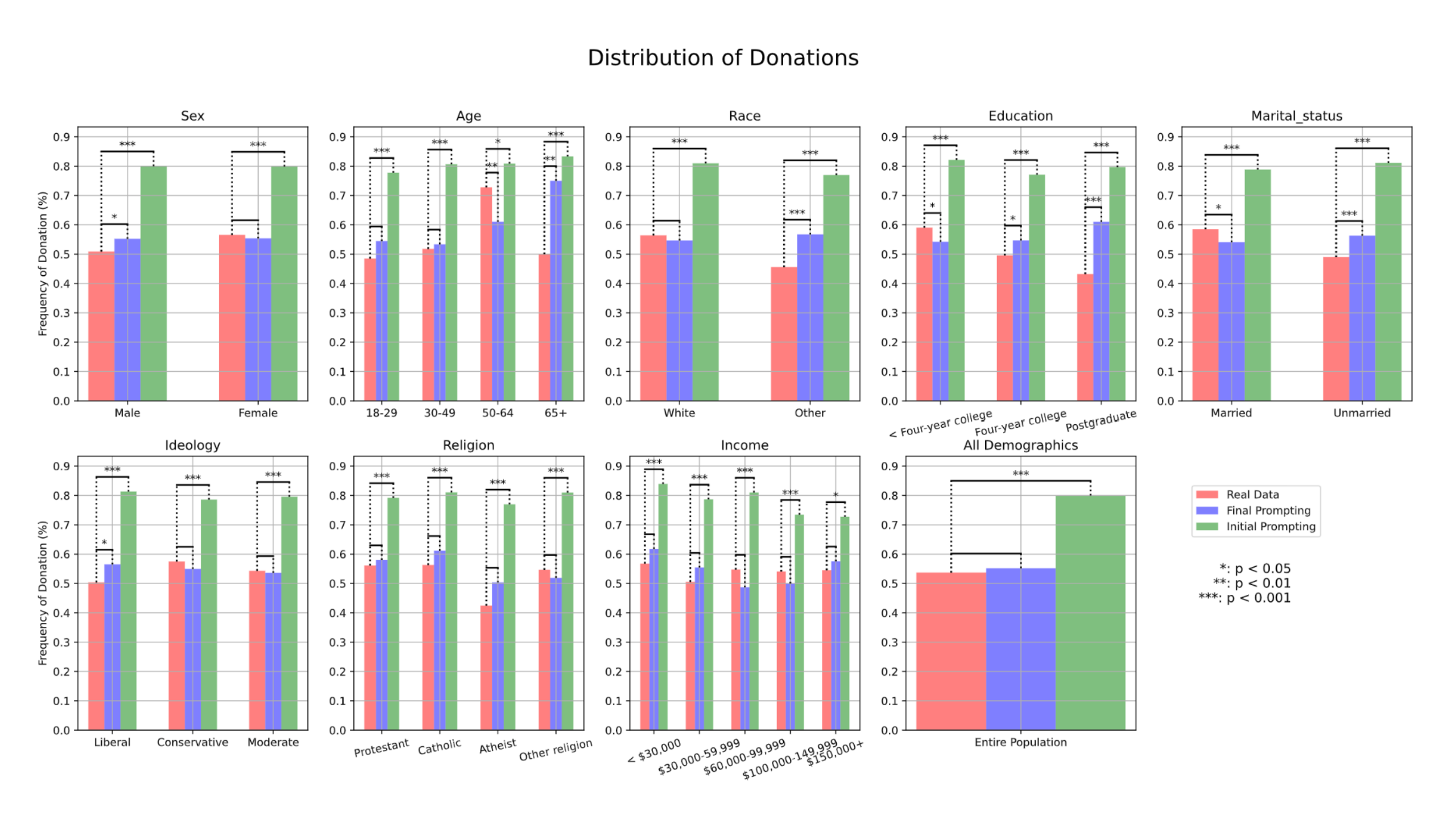
- Generated 1,000 simulated conversations using both the initial and revised prompting strategies.
- Initial prompting resulted in an 80% donation rate, substantially higher than the real human baseline of 54%.
- Revised prompting achieved a 55% donation rate, showing no statistically significant difference from real human behavior.
- As shown in Figure 1, alignment with human donation behavior improved across all demographic groups with the revised prompt, especially for ideology, religion, and income.
Key Findings
- Initial prompts mirrored the original human study instructions, causing GPT-4 to behave overly polite and helpful and produce unrealistically high donation rates.
- The model frequently produced non-human behaviors, including hallucinated charity details and invalid donation amounts exceeding allowed limits.
- Incorporating real demographic profiles and explicit reminders that donation was optional significantly improved the realism of simulated conversations.
- Revised prompting reduced model bias toward donating and better captured human decision-making dynamics.
- Demonstrated that LLMs require fundamentally different prompting strategies than humans to accurately simulate social behavior.
Additional Research
- Simulating human responses to multiple choice questions — Created prompt templates that incorporated demographic attributes to test whether LLMs would answer controversial questions similarly to the humans represented by those demographics.
- Political debate simulations and bias evaluation — Conducted LLM-to-LLM debates on divisive political topics (e.g., abortion, gun control, immigration), assigning one model a Democratic perspective and the other a Republican perspective to analyze persuasion and detect political bias in the models.
Interdisciplinary Computational Health Sciences (Nov 2023 – Apr 2024)
Collaborated in an interdisciplinary research team of Computer Science, Statistics, and Public Health faculty and students to investigate large-scale public health patterns using machine learning and statistical modeling.
My Contributions
- Performed preprocessing and feature engineering for Emergency Room (ER) and Healthy Places Index (HPI) datasets, transforming raw clinical and socioeconomic data into structured inputs for predictive modeling.
- Trained and evaluated multiple machine learning models (LightGBM, XGBoost, Random Forest), analyzing feature importance to identify key predictors contributing to ER diagnoses.
Primary Study: Predicting Maternal Health Complications
- Framed maternal health complication prediction as a binary classification task, modeling whether a patient would experience any complication during pregnancy, labor, or postpartum using merged ER and HPI datasets.
- Implemented and compared four models — Logistic Regression, XGBoost, K-Nearest Neighbors, and a Neural Network — applying feature selection and grid search hyperparameter tuning for each.
Results
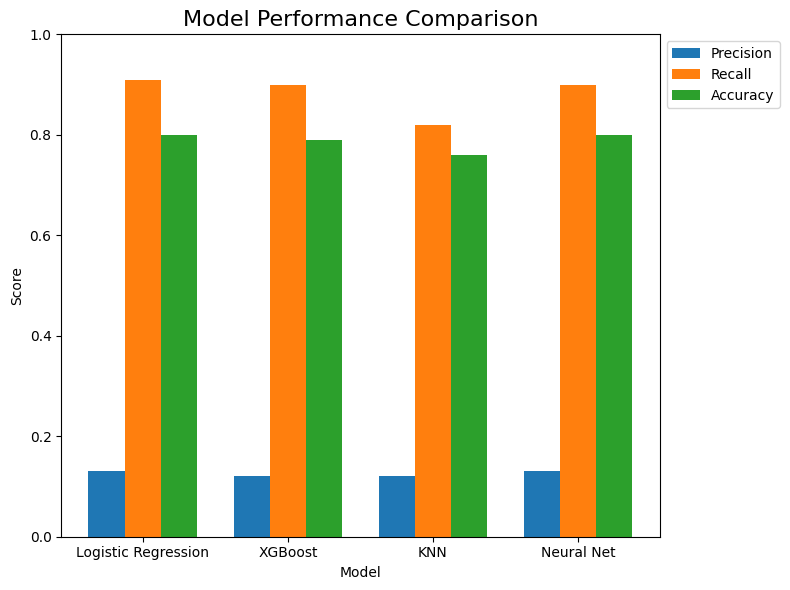
- All models achieved comparable overall accuracy (high 70s–low 80%), with high recall (0.82–0.91) and low precision (0.12–0.13), reflecting substantial class imbalance.
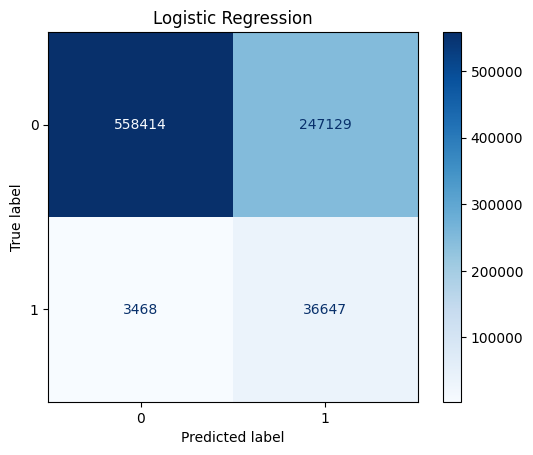
- Confusion matrices confirmed that the models correctly identified most complication cases but over-predicted negatives, consistent with the dataset imbalance.
- Logistic Regression achieved the highest recall among all models while maintaining competitive accuracy.
Key Findings
- Prioritizing recall was clinically important to minimize false negatives, as failing to flag a high-risk patient could delay intervention, whereas false positives allow for preventative monitoring.
- Consistently important predictors across models included age_group, previous C-section, multiple gestation, prolonged pregnancy, and high-risk pregnancy indicators, highlighting key factors for maternal complication risk assessment.
- Logistic Regression was selected as the preferred model due to its high recall and interpretability, providing actionable and transparent guidance for clinical decision-making.
Additional Research
- Exploring Suicide Ideation Risk Factors — Applied LightGBM to identify diagnosis codes with high feature importance for predicting presence of suicidal ideation, supporting early-risk detection analysis.
Capstone-level R&D project (Sept 2023-Apr 2024)
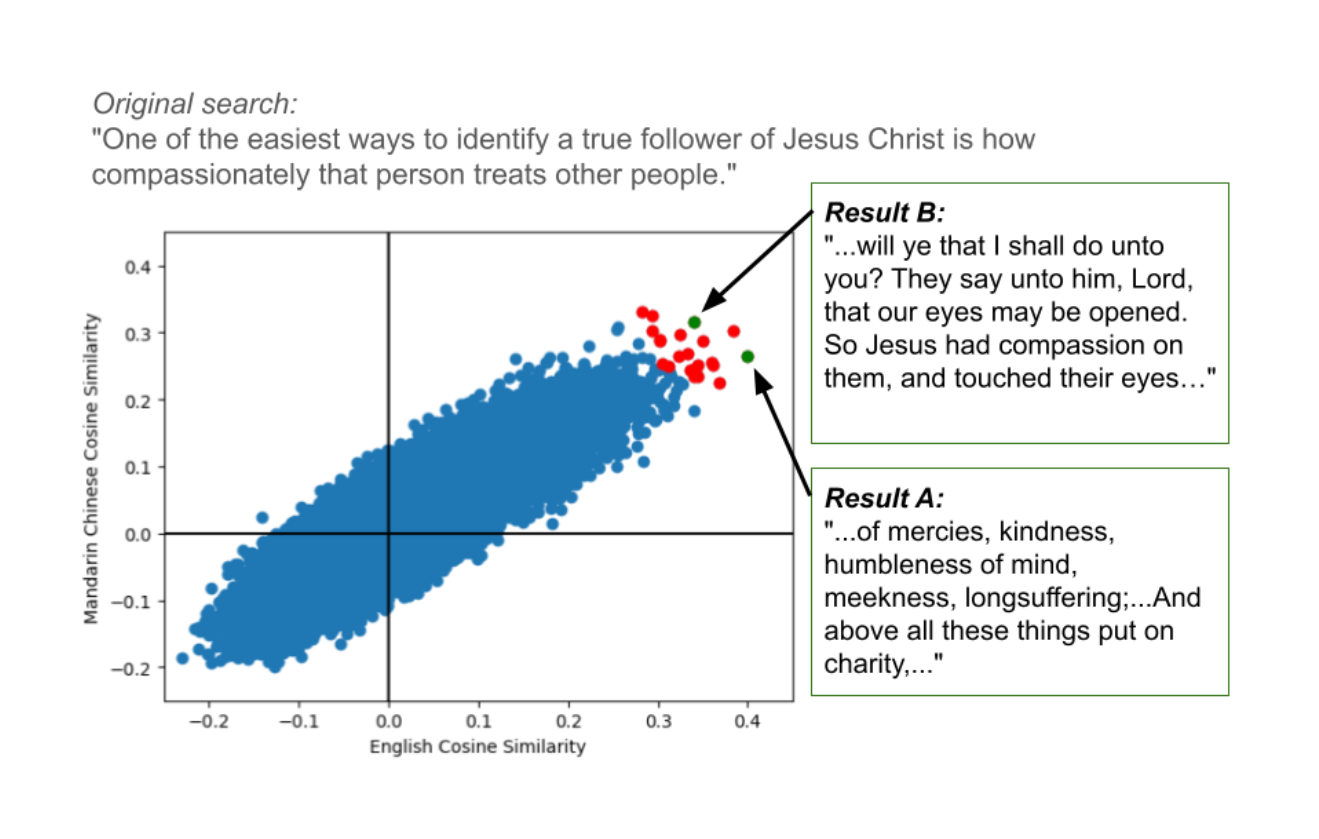
Developed a web application for scripture study featuring cross-lingual semantic search using OpenAI text embeddings. Embedded multilingual queries and aggregated cosine similarity scores to improve passage retrieval and recommendations.
My Contributions
- Implemented a multi-granularity embedding strategy (book-, chapter-, paragraph-, multi-sentence-, sentence-, and word-level) to optimize retrieval precision and contextual relevance.
- Applied KMeans clustering to chapter-level text using sentence embeddings to group thematically similar passages, then computed cosine similarity between cluster centroids and word-level embeddings to infer themes.
- Evaluated multilingual semantic search by translating queries across languages and comparing retrieved passages to assess cross-lingual consistency.
- Collaborated on building and integrating the embedding pipeline into the web application backend.
Key Findings
- Retrieval improved when combining cosine similarity scores from both English and a secondary language. English-only search tended to prioritize similar wording, while other languages better captured semantic meaning. Aggregating both improved overall relevance.
- KMeans clustering effectively grouped thematically similar passages; however, automated theme labeling required additional heuristics (e.g., top 5 word matches per cluster) for interpretability.